构建第一个简单的langgraph项目如下:
.env配置
DEFAULT_LLM_MODEL_NAME:xxx
DEFAULT_LLM_API_KEY:xxx
DEFAULT_LLM_BASE_URL:xxx
1 | import operator |
模块化拆分
project/
├── main.py
├── schemas.py
├── agents/
│ ├── init.py
│ ├── tools.py
│ └── nodes.py
└── graph/
├── init.py
└── workflow.py
schemas.py
是整个系统的 唯一数据源(Single Source of Truth)
使用 Annotated 声明合并策略(如 operator.add 实现消息累积)
1 | from typing import TypedDict, Annotated, Optional |
agent/tools.py
原子能力单元:
使用 LangChain 的 @tool 装饰器封装业务逻辑
每个工具必须有 docstring(供 LLM 理解用途)
1 | from langchain.tools import tool |
agent/nodes.py
Agent 行为节点:
每个函数是一个 状态转换器:state → partial_update
从全局 state 读取输入,返回要更新的字段
1 | from .tools import TOOLS |
graph/workflow.py 流程编排
1 | from .tools import TOOLS |
main.py
1 | from dotenv import load_dotenv |
总结
langgraph框架下,简单的实现了一个分析报告agent,主要模块包括:
- 环境与LLM初始化
- 工具定义
- 状态模型定义
- 节点函数设计
- 图构建
- 运行调用
下一个项目中,我们会增加记忆存储,多agent协同等功能;
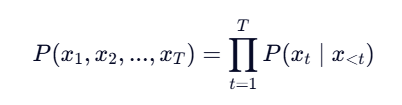 ,使用下一个词预测作为目标。
,使用下一个词预测作为目标。