预训练
从算法的角度来看,大模型预训练(Large Model Pre-training)是指在大规模无标注或弱标注数据集上,通过自监督学习(Self-supervised Learning)等算法策略,对一个参数量巨大的神经网络模型进行初步参数优化的过程。
其核心目标是让模型学习到通用的数据表征能力(如语言的统计规律、语义结构、上下文关系等),为后续的微调(Fine-tuning)或下游任务(如分类、问答、生成等)提供良好的初始化参数。
下面从几个关键算法维度来诠释大模型预训练:
1. 目标函数设计:自监督学习
大模型预训练通常不依赖人工标注标签,而是通过构造代理任务(pretext tasks)从原始数据中自动生成监督信号。典型例子包括:
语言建模(Language Modeling):
自回归语言模型(如 GPT 系列):最大化序列的联合概率: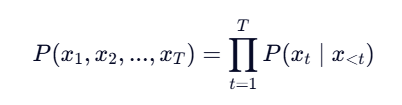 ,使用下一个词预测作为目标。
,使用下一个词预测作为目标。
掩码语言建模(Masked Language Modeling, MLM,如 BERT):随机掩盖输入中的一些 token,让模型预测被掩盖的内容
对比学习(Contrastive Learning):
在某些多模态大模型(如 CLIP)中,通过最大化正样本对(如图文对)的相似度,同时最小化负样本对的相似度,构建 InfoNCE 等损失函数。
这些目标函数本质上是在没有人工标签的情况下,从数据本身挖掘结构信息,从而驱动模型学习有意义的表示。
2. 模型架构:Transformer 为核心
当前主流的大模型几乎都基于 Transformer 架构,因其具备以下优势:
并行计算能力强:相比 RNN,Transformer 可以高效利用 GPU/TPU 进行大规模并行训练。
长距离依赖建模:通过自注意力机制(Self-Attention),模型能捕捉任意两个 token 之间的依赖关系。
可扩展性好:通过堆叠更多层、扩大隐藏维度、增加注意力头数等方式,可以轻松扩展至百亿甚至万亿参数规模。
3. 优化算法与训练策略
由于模型规模巨大、数据量庞大,预训练对优化算法和工程实现提出极高要求:
优化器:常用 AdamW(带权重衰减的 Adam),因其在大规模训练中表现稳定。
学习率调度:采用 warmup + decay 策略(如线性 warmup 后余弦退火),避免初期训练不稳定。
梯度裁剪(Gradient Clipping):防止梯度爆炸。
混合精度训练(Mixed Precision):使用 FP16/FP8 加速计算并节省显存。
分布式训练:结合数据并行、模型并行、流水线并行(如 ZeRO、Megatron-LM、DeepSpeed)等技术,在数千 GPU 上协同训练。
4. 数据规模与泛化能力
预训练的一个关键假设是:更大的数据 + 更大的模型 → 更强的泛化能力。算法上体现为:
模型在海量文本(如 Common Crawl、The Pile、WuDao 等)上学习到丰富的语言知识(语法、事实、推理模式等)。
遵循 scaling law(缩放律):在一定范围内,验证损失随模型参数量、数据量、计算量的幂律下降。
5. 预训练 vs 微调的算法角色
预训练阶段:学习通用表示(representation learning),属于“基础能力”构建。
微调阶段:在特定任务的小规模标注数据上,通过有监督学习调整部分或全部参数,实现任务适配。
近年来也出现无需微调的范式(如 Prompting、In-context Learning),但其有效性仍依赖于高质量的预训练。
总结(算法视角)
大模型预训练 = 自监督目标函数 + Transformer 架构 + 大规模优化算法 + 海量数据驱动的表示学习
它本质上是一种无监督表示学习算法,通过在超大规模数据上优化精心设计的代理任务,使模型内化世界知识与结构规律,从而为各类下游任务提供强大的先验能力。